Xin Dong

Cambridge, MA, May 2020 |
I am a research scientist at NVIDIA Research. I received Ph.D. in Computer Science from Harvard University in 2023, advised by H.T. Kung. I have general research interests in deep learning, with a focus on designing accurate, efficient and trustworthy systems for autonomous machines, LLM and GenAI. Prior to Harvard, I was a research assistant at Nanyang Technological University and UC San Diego. I am a recipient of the Harvard James Miller Peirce Fellowship.
Email: firstnamelastname [at] g.harvard.edu Research intern positions at NVIDIA available for summer/fall 2024 focused on foundation models. Please drop a CV if interested. |
News
- Jan 2024 » Serve as Editor, Area Chair and Review for ICLR, NeurIPS, ACM MM, and Electronics.
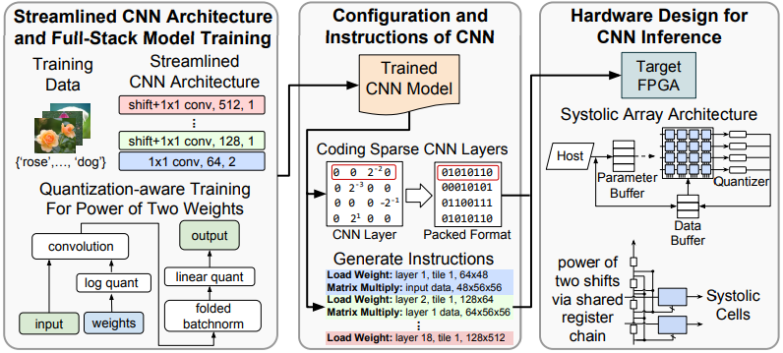
- Oct 2022 » Our Additive Power-of-Two Quantization (ICLR'20) is now supported by offical PyTorch APIs. It is a non-uniform quantization that fits well to weights distribution and offers great hardware efficiency. Try it out! 🔥
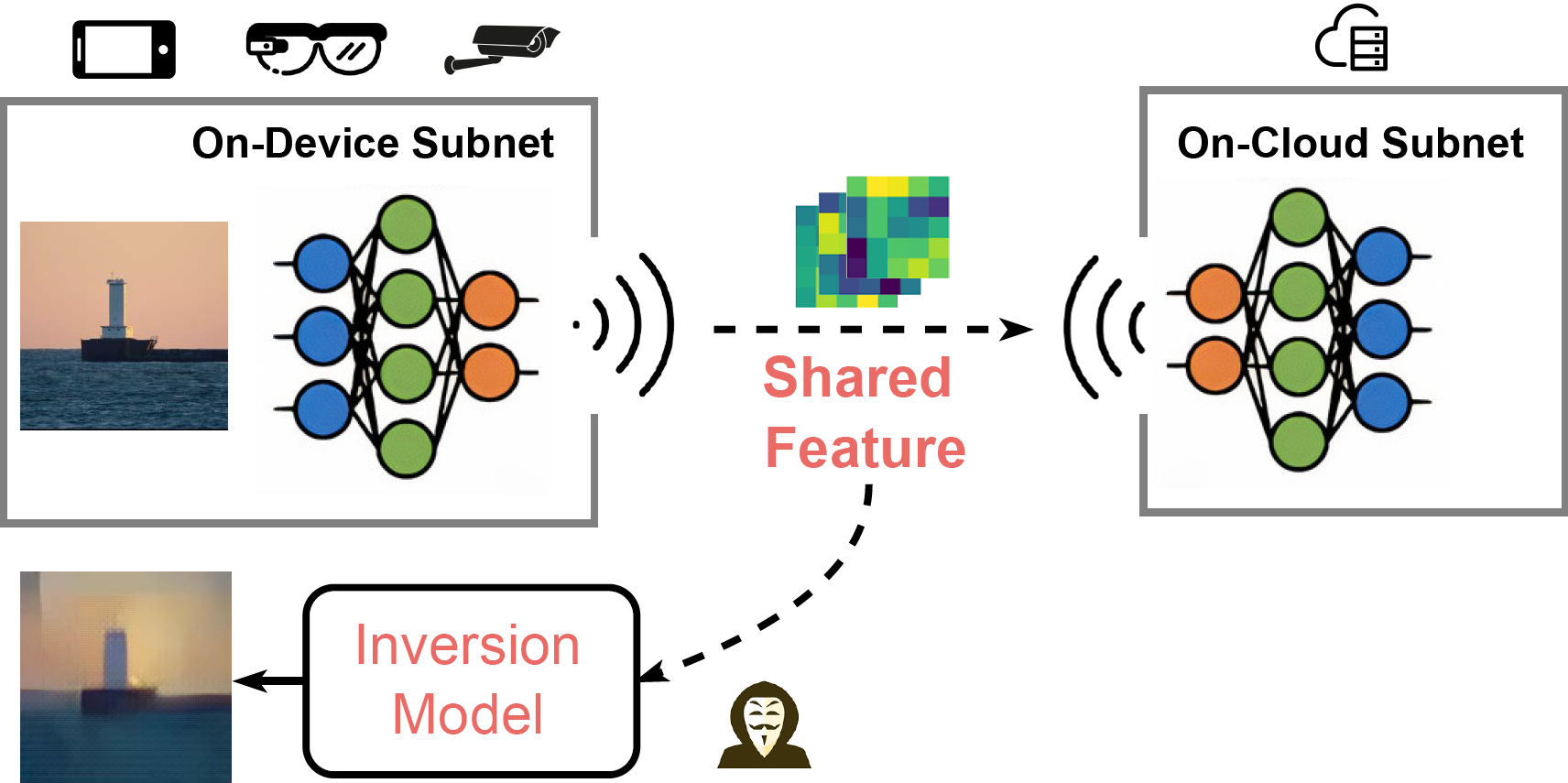
- Oct 2022 » Our Direct Model Inversion is accepted by BMVC 2022 and featured by MIT Technology Review, SingularityHub. Thank collaborators from NVIDIA and Harvard.
- Jul 2022 » Our paper on federated learning is accepted by ECCV 2022. Thank collaborators from Harvard and Deepmind.
- Mar 2022 » The Co-organized workshop on The Practical Deep Learning in the Wild (PracticalDL-22) at AAAI 2022 is online now!
- Mar 2022 » Two first-author papers are accepted by CVPR 2022. Thanks collaborators from Meta, Deepmind, Harvard and UTD.
Experiences



Publications

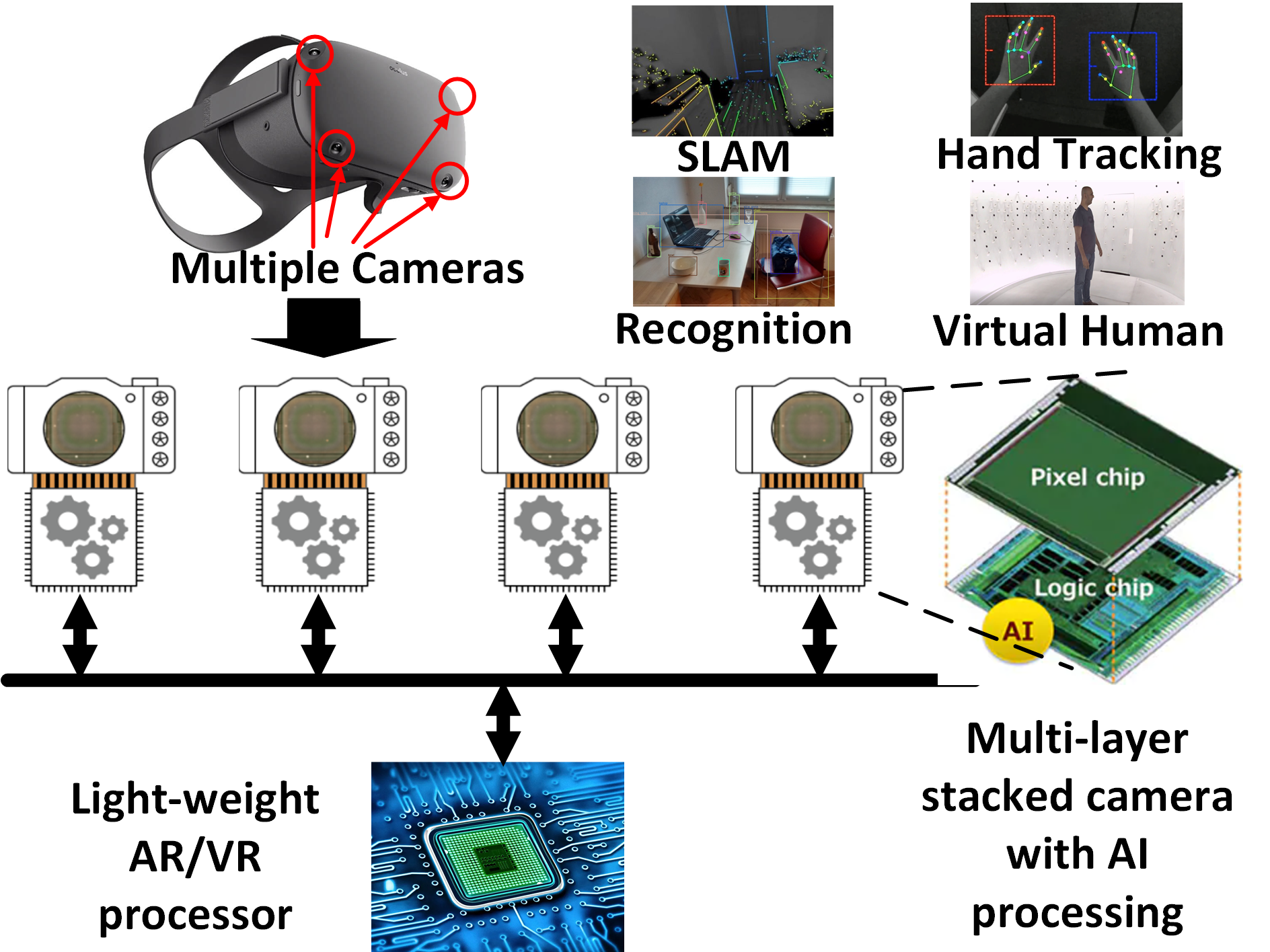
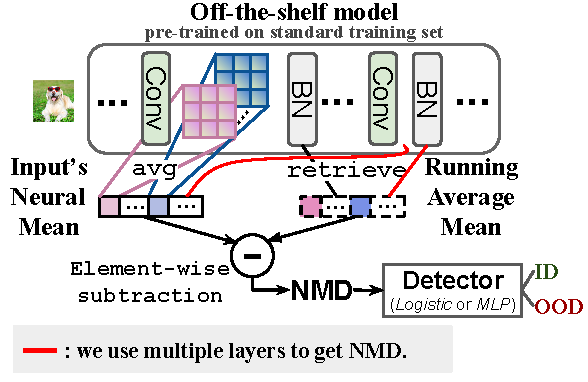
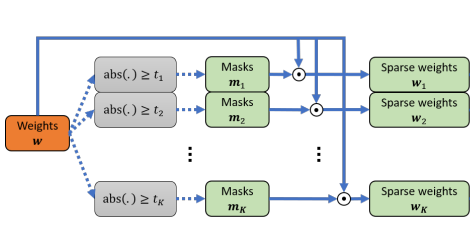
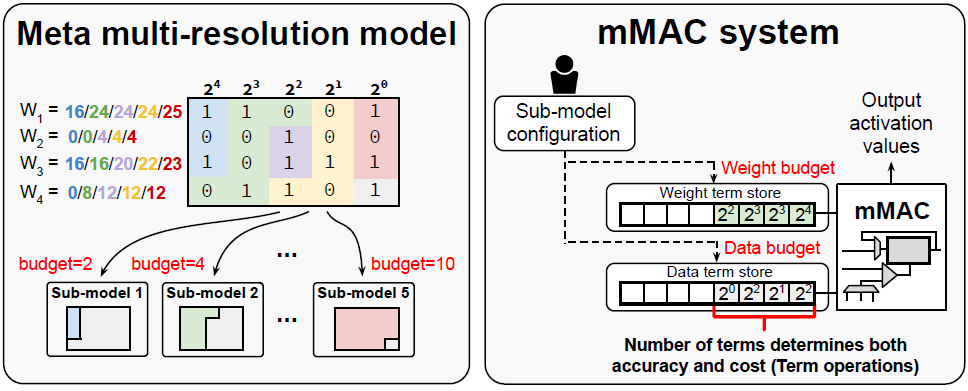
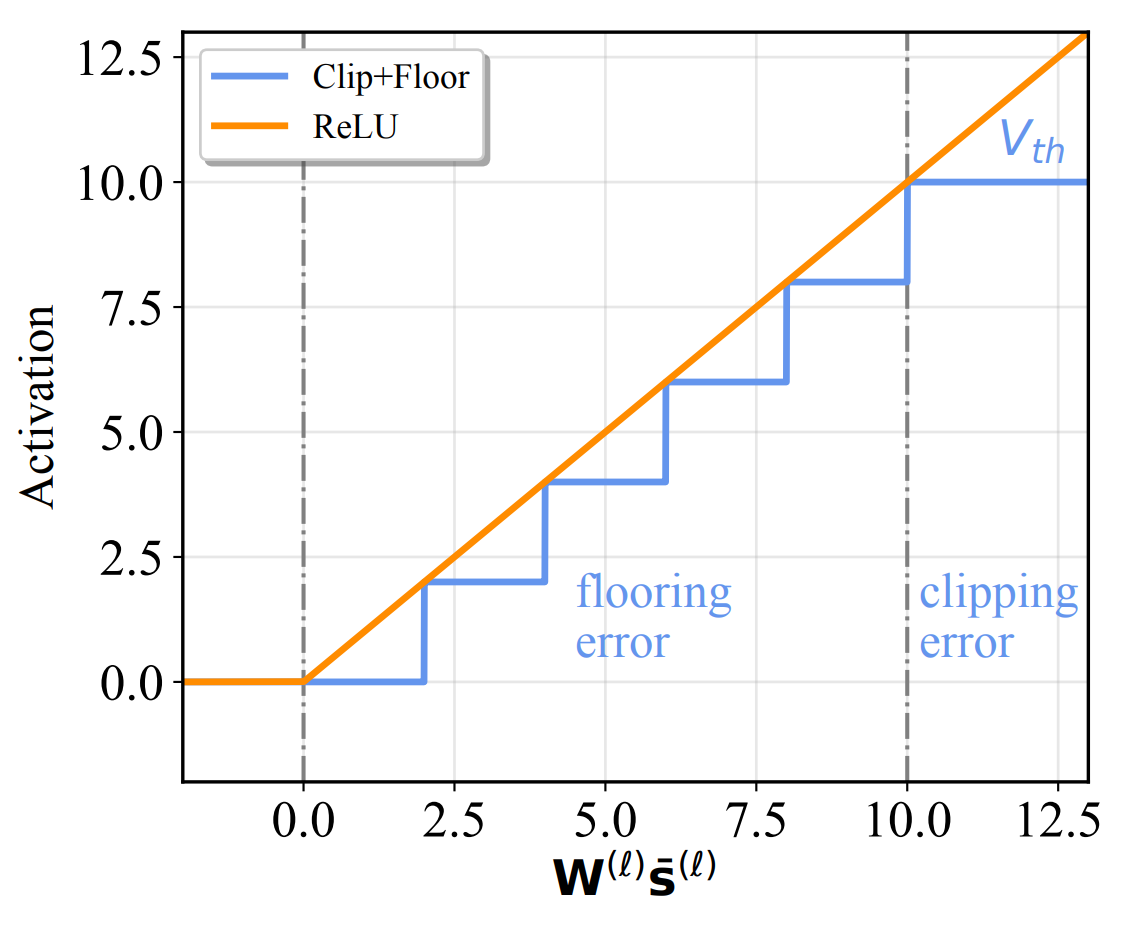

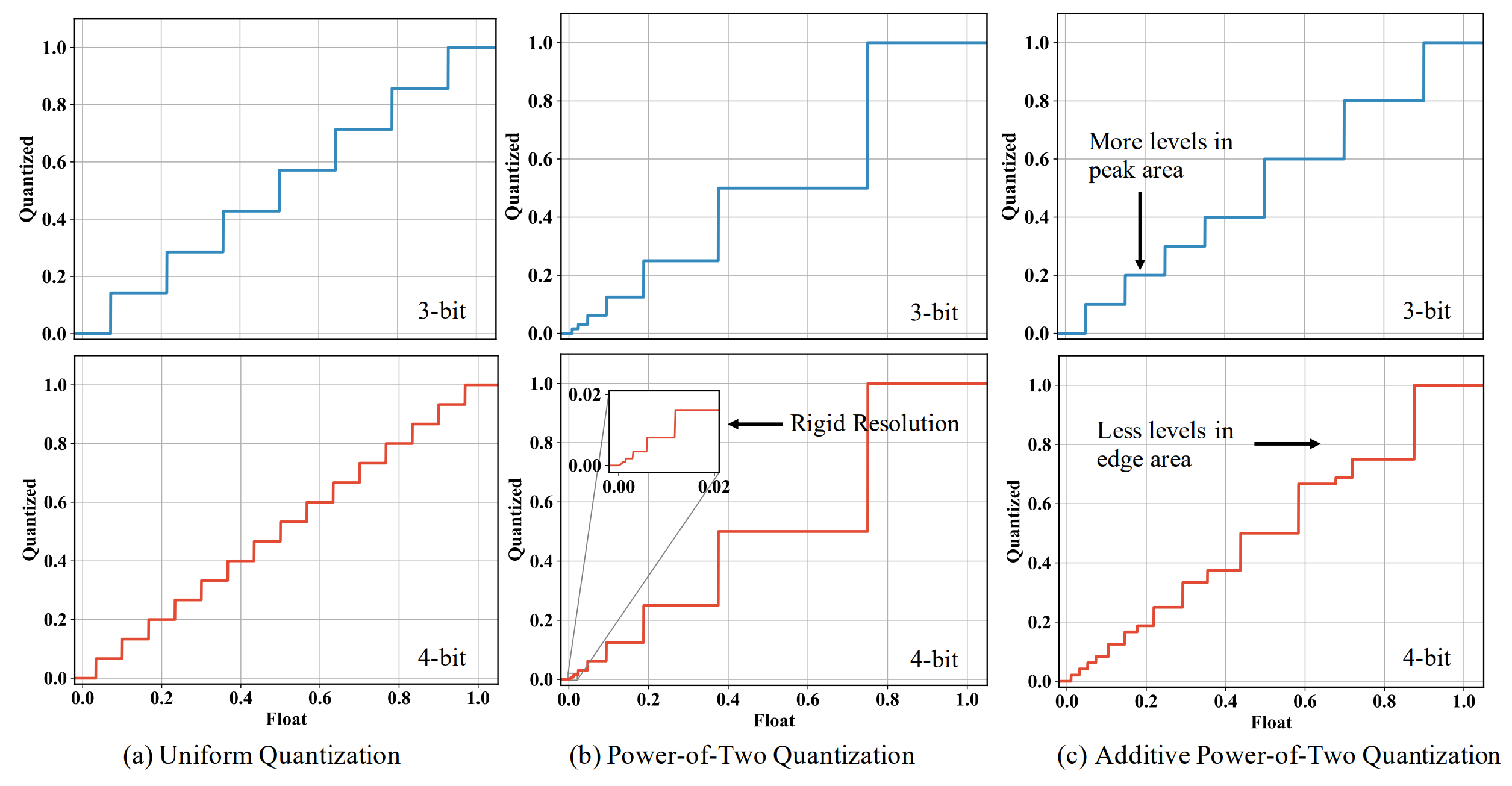
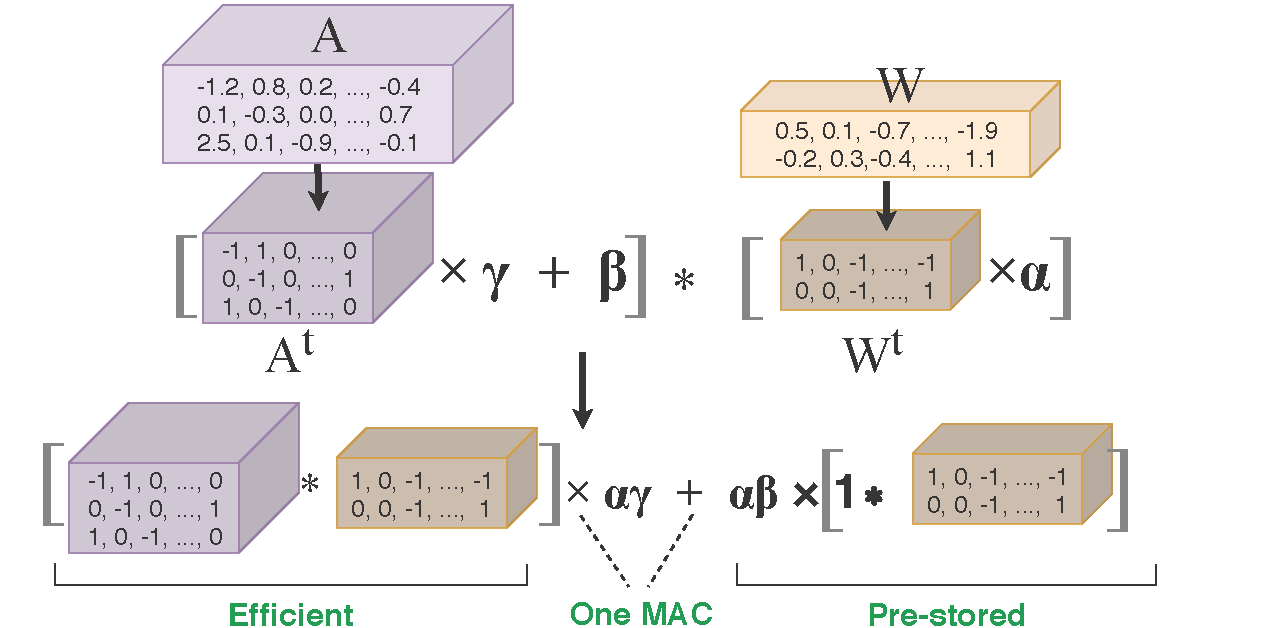
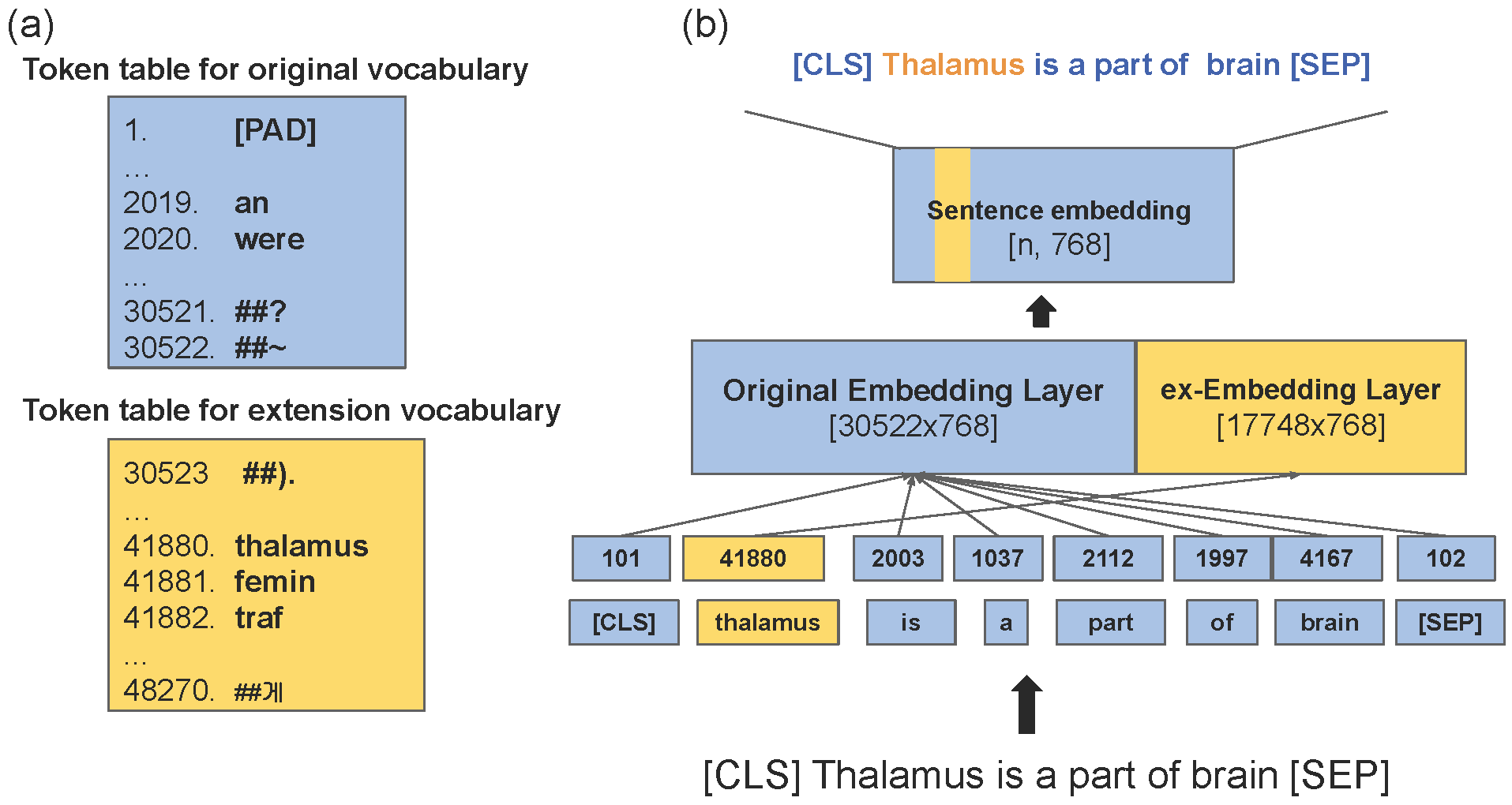
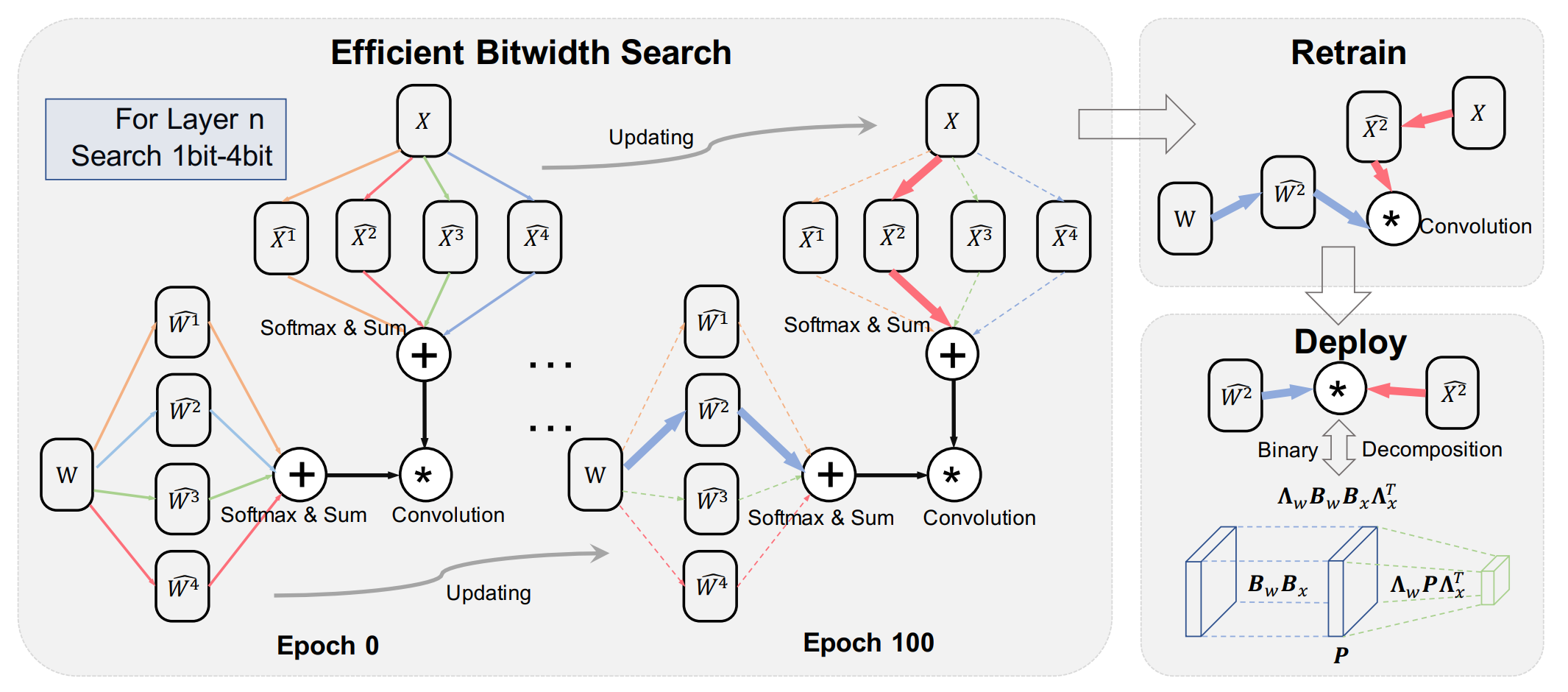
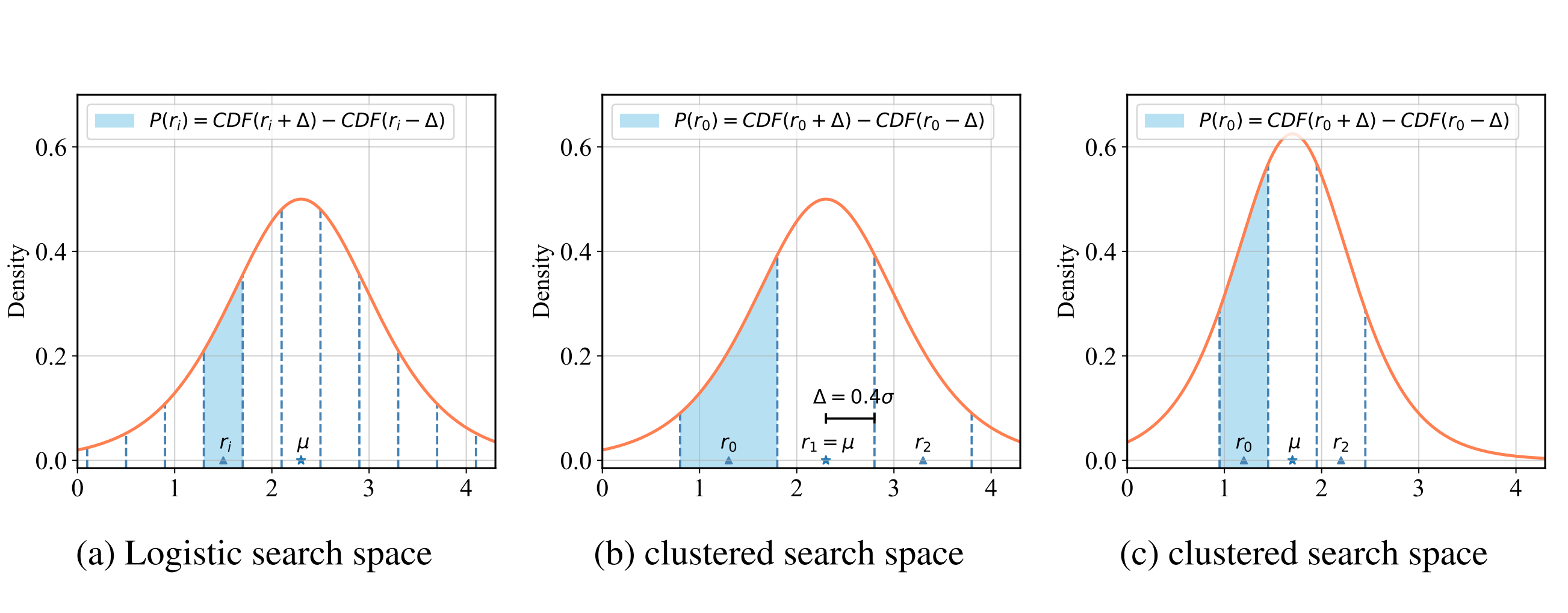
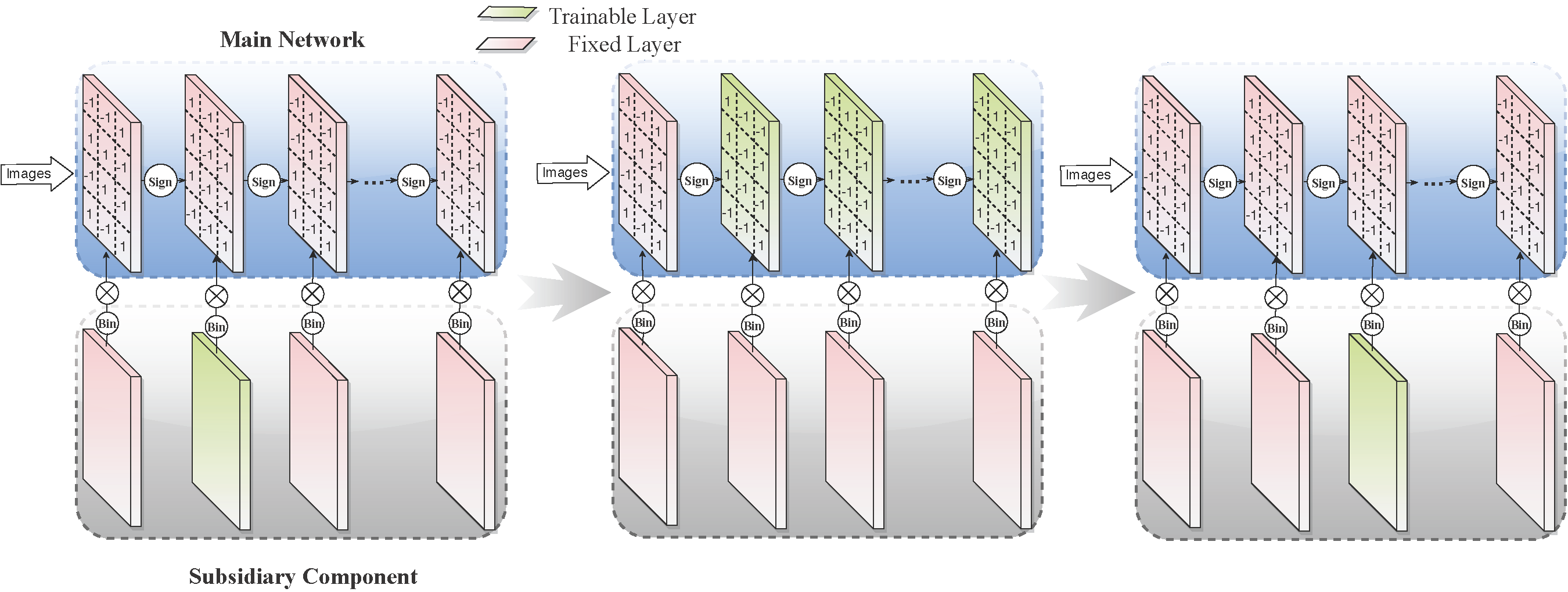
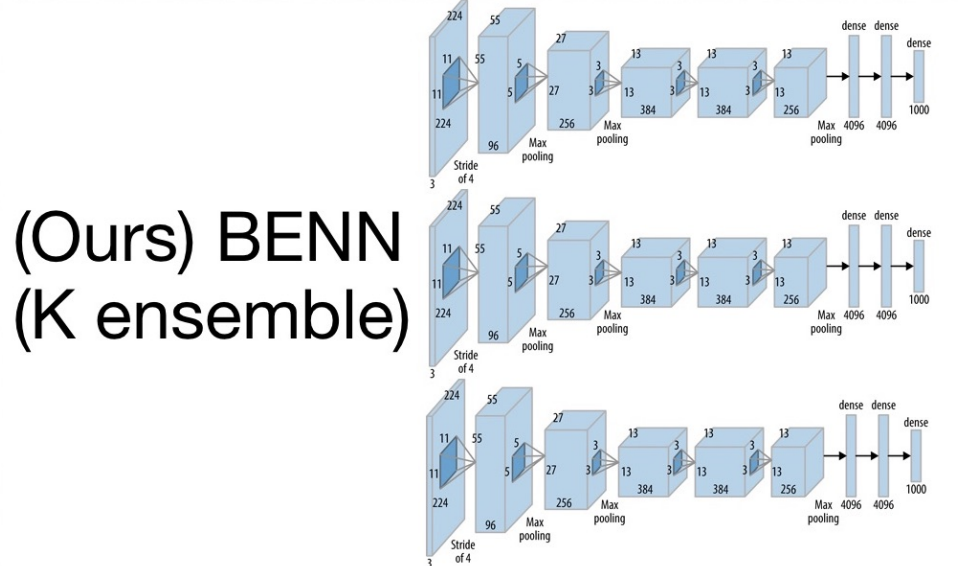
Academic Services
- Reviewer for ICML, NeurIPS, AAAI, IJCAI, CVPR, ICCV, ECCV, EMNLP, ACL
- Co-organizer of the 1st international workshop on The Practical Deep Learning in the Wild (PracticalDL-22) at AAAI 2022
- Teaching Fellow of Harvard CS242 Compute at Scale